أنظمة السلسلة المتعاقبة التي تمرّر الكلام عبر نموذج لغة كبير (LLM) تكون أكثر معرفة، لكن تأخير الأنابيب طويل بما يكفي لجعل المحادثة تبدو متقطعة وروبوتية. الباحثون في Sakana AI، مختبر الذكاء الاصطناعي في طوكيو، يقدّمون KAME (Knowledge-Access Model Extension)، بنية هجينة تحافظ على زمن استجابة شبه صفرية للنظام المباشر لتحويل الكلام إلى كلام بينما تُدمج المعرفة الغنية لنموذج لغة كبير في الوقت الفعلي.

المشكلة: نمطان، مقايضتان
لفهم أهمية KAME، من المفيد معرفة التصميمين السائدين الذين يجسّرهما. نموذج S2S مباشر مثل Moshi (من تطوير KyutAI) هو محول أحادي يُدخل رموز صوتية ويُنتج رموزًا صوتية في حلقة مستمرة. نظرًا لعدم الحاجة إلى المزامنة مع أنظمة خارجية، يكون زمن الاستجابة منخفضًا جدًا — في كثير من الاستفسارات يبدأ النموذج بالتحدث قبل أن ينتهي المستخدم من سؤاله. لكن الإشارات الصوتية أكثر كثافة معلوماتيًا من النص، لذا يضطر النموذج إلى تخصيص قدرة كبيرة لنمذجة الخصائص الصوتية مثل النبرة والعاطفة والإيقاع، مما يقلل من مساحة المعرفة الفعلية والتفكير العميق.
من ناحية أخرى، تُوجّه الأنظمة المتسلسلة كلام المستخدم عبر نموذج التعرف التلقائي على الكلام (ASR)، ثم يُحوَّل النص الناتج إلى نموذج لغة كبير قوي، وأخيرًا يُحوَّل رد النموذج إلى كلام عبر محرك تحويل النص إلى كلام (TTS). جودة المعرفة تكون ممتازة — يمكن ربط أي نموذج لغة متقدم — لكن النظام يجب أن ينتظر انتهاء المستخدم من الكلام قبل أن يبدأ معالجة ASR وLLM. النتيجة هي متوسط تأخير يقارب 2.1 ثانية، وهو ما يقطع تدفق المحادثة الطبيعي.
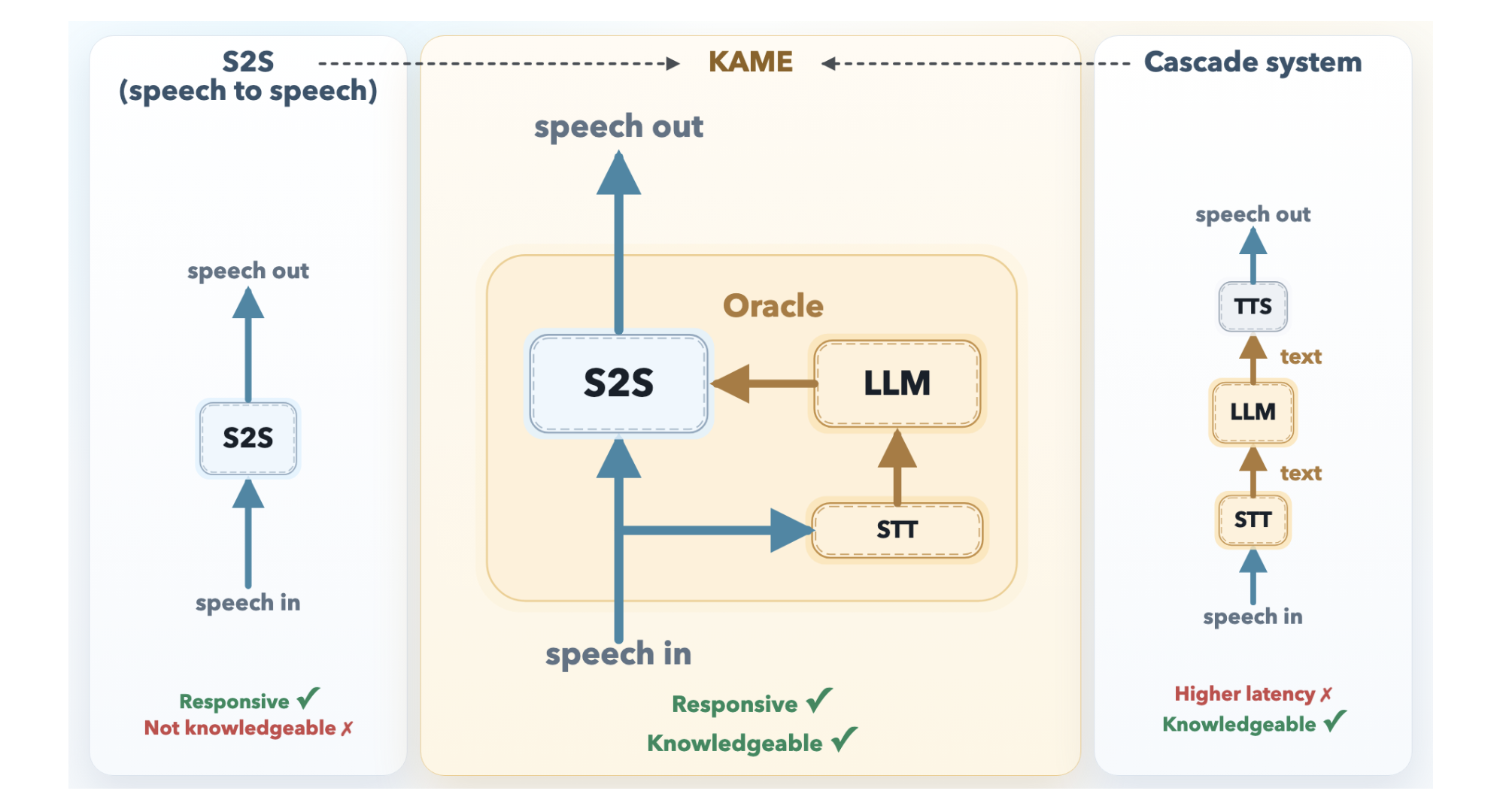
معمارية KAME: التحدث أثناء التفكير
يعمل KAME كنظام مزدوج مع مكوّنين غير متزامنين يعملان بالتوازي. وحدة S2S الأمامية تستند إلى بنية Moshi وتُعالج الصوت في الوقت الفعلي بدورة رموز صوتية منفصلة (حوالي كل 80 مللي ثانية). يبدأ في توليد استجابة منطوقة فورًا.
داخل Moshi، التصميم الأصلي يتضمن ثلاث تدفقات — الصوت المدخل، المونولوج الداخلي (نص)، والصوت المخرج — وقد أُضيف في KAME تدفق رابع: تدفق الـ oracle. هذه هي نقطة الابتكار الرئيسية.

يتكوّن المكوّن الخلفي من نموذج تحويل الكلام إلى نص (STT) متدفّق مقترن بنموذج لغة كامل. أثناء تحدث المستخدم، يبني مكوّن STT نصًا جزئيًا باستمرار ويرسله دوريًا إلى النموذج الخلفي. لكل نص جزئي يتلقاه، يولّد النموذج ردًا نصيًا مرشحًا يُسمّى oracle، ويُعيده إلى الواجهة الأمامية. بما أن كلام المستخدم لا يزال يتدفق، تبدأ الـ oracles كتخمينات مُعلمة وتصبح أكثر دقة مع اكتمال النص.
بعد ذلك، يُشَرط محوّل S2S الأمامي مخرجاته الصوتية المستمرة على سياقه الداخلي وعلى رموز الـ oracle الواردة. عندما يصل oracle جديد وأفضل، يستطيع النموذج تعديل استجابته — فعليًا يُحدّث الكلام وسط الجملة، كما يفعل الإنسان.
نظرًا لتشغيل كلا المكوّنين بشكل غير متزامن ومستقل، يبقى زمن الاستجابة الأولية شبه صفر.
التدريب باستخدام Oracles محاكاة
تحدٍ واحد هو عدم وجود مجموعة بيانات طبيعية تحتوي على إشارات oracle. يواجه فريق بحث Sakana AI هذا التحدي بتقنية تُسمّى Simulated Oracle Augmentation. باستخدام نموذج “محاكي” LLM ومجموعة بيانات محادثات قياسية (مُدخل المستخدم + الرد الحقيقي)، يولّد الفريق سلاسل oracle اصطناعية تحاكي ما قد ينتجه نموذج لغة في الوقت الفعلي عبر مستويات مختلفة من اكتمال النص.
يُعرّفون ست مستويات إرشاد (0–5)، من تخمين عشوائي تمامًا في المستوى 0 إلى الرد النصي الكامل في المستوى 5. بُنيت بيانات التدريب لـ KAME من 56,582 حوارًا اصطناعيًا مأخوذًا من MMLU‑Pro وGSM8K وHSSBench، تم تحويلها إلى صوت عبر TTS وتزويدها بسلاسل oracle المت progressive.
النتائج: جودة شبه متسلسلة، زمن استجابة شبه صفر
تقييمات على مجموعة فرعية مُحوّلة صوتيًا من معيار MT‑Bench متعدد الجولات (فئات التفكير، STEM، والإنسانيات) أظهرت تحسينًا كبيرًا. سجل Moshi وحده متوسط 2.05. KAME مع gpt‑4.1 كخلفية حصل على 6.43، وKAME مع claude‑opus‑4‑1 حصل على 6.23 — كلاهما بنفس زمن استجابة Moshi.
النظام المتسلسل الرائد Unmute (مدعوم أيضًا بـ gpt‑4.1) سجل 7.70، لكن بمتوسط تأخير 2.1 ثانية مقارنةً بصفر تقريبًا لـ KAME.
لعزل قدرة النموذج الخلفي عن تأثير التوقيت، قيّم الفريق ردود النص للنموذج الخلفي من آخر حقن oracle في كل جلسة KAME مباشرةً — متجاوزًا مشكلة التوليد المبكر. متوسط هذه الدرجات كان 7.79 (تفكير 6.48، STEM 8.34، إنسانيات 8.56)، وهو ما يقارب نتيجة Unmute.
هذا يؤكد أن الفجوة بين KAME والأنظمة المتسلسلة ليست بسبب حد المعرفة في النموذج الخلفي، بل نتيجة بدء الكلام قبل استكمال استفسار المستخدم بالكامل.
المرونة في اختيار النموذج الخلفي
KAME مستقل تمامًا عن النموذج الخلفي. تم تدريب الواجهة الأمامية باستخدام gpt‑4.1‑nano كنموذج أساسي، لكن استبدالها بـ claude‑opus‑4‑1 أو gemini‑2.5‑flash أثناء الاستدلال لا يتطلب إعادة تدريب.
في تجارب Sakana AI، تفوّق claude‑opus‑4‑1 على gpt‑4.1 في مهام التفكير، بينما سجل gpt‑4.1 أعلى في أسئلة الإنسانيات — ما يُتيح للمُطوّرين توجيه الاستفسارات إلى النموذج الأنسب دون تعديل الواجهة الأمامية.
خلاصة
يجسّـد KAME حلًا للمعادلة بين السرعة والمعرفة في الذكاء الاصطناعي للمحادثة عبر تشغيل نموذج تحويل الكلام إلى كلام أمامي ونموذج لغة خلفي بشكل غير متزامن ومتوازي — يرد النموذج الأمامي فورًا بينما يحقن النموذج الخلفي إشارات oracle محسّنة تدريجيًا في الوقت الفعلي، محوّلًا النمط من “التفكير ثم الكلام” إلى “الكلام أثناء التفكير”. الارتفاع في الدرجات (من 2.05 إلى 6.43) يقترب من أداء الأنظمة المتسلسلة دون أي تكلفة زمنية.
